## 시작하기: 실험 추적하기
### 가입하고 API 키 생성하기
API 키를 사용하면 머신을 W\&B에 인증할 수 있습니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
### `wandb` 라이브러리 설치 및 로그인
로컬에 `wandb` 라이브러리를 설치하고 로그인하려면 다음 단계를 따르세요.
### 프로젝트 이름 지정하기
W\&B 프로젝트는 관련 run에서 로깅된 모든 차트, 데이터, 모델이 저장되는 곳입니다. 프로젝트에 이름을 지정하면 작업을 더 체계적으로 정리하고, 하나의 프로젝트에 관한 모든 정보를 한곳에서 관리할 수 있습니다.
프로젝트에 run을 추가하려면 `WANDB_PROJECT` 환경 변수를 프로젝트 이름으로 설정하면 됩니다. `WandbCallback`은 이 프로젝트 이름 환경 변수를 읽어 run을 설정할 때 사용합니다.
### 트레이닝 run을 W\&B에 로깅하기
코드에서든 명령줄에서든 `Trainer`의 트레이닝 인수를 정의할 때 **가장 중요한 단계는** W\&B 로깅을 활성화할 수 있도록 `report_to`를 `"wandb"`로 설정하는 것입니다.
`TrainingArguments`의 `logging_steps` 인수는 트레이닝 중 트레이닝 메트릭이 W\&B에 얼마나 자주 전송되는지를 제어합니다. `run_name` 인수를 사용해 W\&B에서 트레이닝 run의 이름을 지정할 수도 있습니다.
이제 끝입니다. 이제 모델이 트레이닝되는 동안 loss, 평가 메트릭, 모델 토폴로지, 그라디언트를 W\&B에 로깅합니다.
### 모델 체크포인트 저장 사용 설정
[Artifacts](/ko/models/artifacts/)를 사용하면 모델과 데이터셋을 최대 100GB까지 무료로 저장한 다음 W\&B [레지스트리](/ko/models/registry/)를 사용할 수 있습니다. 레지스트리를 사용하면 모델을 등록해 탐색하고 평가할 수 있으며, 스테이징을 준비하거나 프로덕션 환경에 배포할 수도 있습니다.
Hugging Face 모델 체크포인트를 Artifacts에 로그하려면 `WANDB_LOG_MODEL` 환경 변수를 다음 값 중 *하나* 로 설정하세요.
* **`checkpoint`**: [`TrainingArguments`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments)의 `args.save_steps`마다 체크포인트를 업로드합니다.
* **`end`**: `load_best_model_at_end`도 설정된 경우 트레이닝이 끝날 때 모델을 업로드합니다.
* **`false`**: 모델을 업로드하지 않습니다.
#### W\&B Registry
체크포인트를 Artifacts에 로깅한 후에는 [레지스트리](/ko/models/registry/)를 사용해 최고 성능의 모델 체크포인트를 등록하고 팀 전체에서 중앙 관리할 수 있습니다. 레지스트리를 사용하면 작업별로 최고 성능의 모델을 구성하고, 모델 수명 주기를 관리하며, 전체 ML 수명 주기를 추적하고 감사하고, 후속 작업을 [자동화](/ko/models/automations/)할 수 있습니다.
모델 아티팩트를 연결하려면 [레지스트리](/ko/models/registry/)를 참고하세요.
### 트레이닝 중 평가 출력 시각화
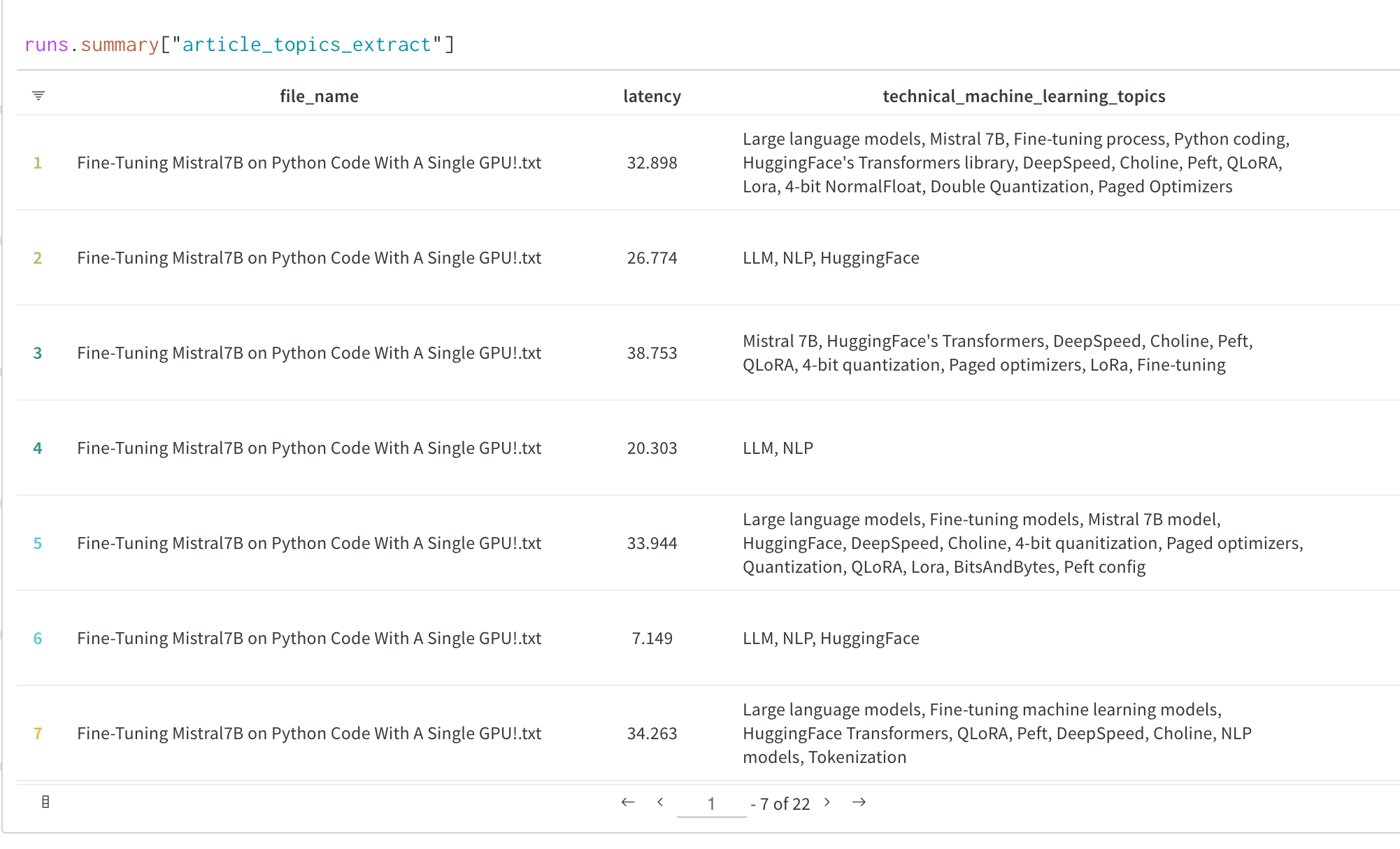
트레이닝이나 평가 중에 모델 출력을 시각화하면 모델이 어떻게 트레이닝되고 있는지 제대로 이해하는 데 큰 도움이 되는 경우가 많습니다.
Transformers Trainer의 콜백 시스템을 사용하면 모델의 텍스트 생성 출력이나 기타 예측 같은 유용한 추가 데이터를 W\&B Tables에 로깅할 수 있습니다.
트레이닝 중 평가 출력을 로깅해 아래와 같은 W\&B Table에 기록하는 방법에 대한 전체 가이드는 아래의 [맞춤형 로깅 섹션](#custom-logging-log-and-view-evaluation-samples-during-training)을 참조하세요:
### W\&B run 종료하기(노트북 전용)
트레이닝이 Python 스크립트 안에서 실행된다면, 스크립트가 끝날 때 W\&B run도 함께 종료됩니다.
Jupyter 또는 Google Colab 노트북을 사용하는 경우에는 `run.finish()`를 호출해 트레이닝이 끝났음을 알려야 합니다.
```python theme={null}
run = wandb.init()
trainer.train() # W&B에 트레이닝 및 로깅 시작
# 사후학습(Post-training) 분석, 테스트, 기타 로깅 코드
run.finish()
```
### 결과 시각화하기
트레이닝 결과를 로깅한 후에는 [W\&B 대시보드](/ko/models/track/workspaces/)에서 결과를 동적으로 탐색할 수 있습니다. 수십 개의 run을 한 번에 쉽게 비교하고, 흥미로운 결과를 확대해 자세히 살펴보며, 유연한 대화형 시각화를 통해 복잡한 데이터에서 인사이트를 끌어낼 수 있습니다.
## 고급 특성과 자주 묻는 질문
### 가장 성능이 좋은 모델은 어떻게 저장하나요?
`Trainer`에 `load_best_model_at_end=True`가 포함된 `TrainingArguments`를 전달하면, W\&B가 성능이 가장 좋은 모델 checkpoint를 Artifacts에 저장합니다.
모델 checkpoint를 Artifacts로 저장하면 [레지스트리](/ko/models/registry/)로 승격할 수 있습니다. 레지스트리에서는 다음과 같은 작업을 할 수 있습니다:
* ML 작업별로 가장 성능이 좋은 모델 버전을 구성합니다.
* 모델을 중앙에서 관리하고 팀과 공유합니다.
* 모델을 프로덕션에 맞게 스테이징하거나 추가 평가을 위해 북마크합니다.
* 다운스트림 CI/CD 프로세스를 트리거합니다.
### 저장한 모델은 어떻게 불러오나요?
`WANDB_LOG_MODEL`을 사용해 모델을 W\&B Artifacts에 저장했다면, 추가 트레이닝을 하거나 Inference를 실행하기 위해 모델 가중치를 다운로드할 수 있습니다. 그런 다음 이전에 사용한 것과 동일한 Hugging Face 아키텍처에 다시 로드하면 됩니다.
```python theme={null}
# 새 run 생성
with wandb.init(project="amazon_sentiment_analysis") as run:
# 아티팩트의 이름과 버전 전달
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run.use_artifact(my_model_name)
# 모델 가중치를 폴더에 다운로드하고 경로 반환
model_dir = my_model_artifact.download()
# 동일한 모델 클래스를 사용하여
# 해당 폴더에서 Hugging Face 모델 로드
model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# 추가 트레이닝 수행 또는 Inference 실행
```
### 체크포인트에서 트레이닝을 재개하려면 어떻게 하나요?
`WANDB_LOG_MODEL='checkpoint'`를 설정한 경우, `TrainingArguments`에서 `model_dir`를 `model_name_or_path` 인수로 사용하고 `Trainer`에 `resume_from_checkpoint=True`를 전달해 트레이닝을 재개할 수도 있습니다.
```python theme={null}
last_run_id = "xxxxxxxx" # wandb workspace에서 run_id를 가져옵니다
# run_id로 wandb run을 재개합니다
with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# run에 아티팩트를 연결합니다
my_checkpoint_name = f"checkpoint-{last_run_id}:latest"
my_checkpoint_artifact = run.use_artifact(my_model_name)
# 체크포인트를 폴더에 다운로드하고 경로를 반환합니다
checkpoint_dir = my_checkpoint_artifact.download()
# 모델과 trainer를 다시 초기화합니다
model = AutoModelForSequenceClassification.from_pretrained(
"
### 트레이닝 중 평가 샘플을 로깅하고 확인하려면 어떻게 해야 하나요
Transformers `Trainer`를 통해 W\&B에 로깅하는 작업은 Transformers 라이브러리의 [`WandbCallback`](https://huggingface.co/transformers/main_classes/callback.html#transformers.integrations.WandbCallback)에서 처리합니다. Hugging Face 로깅을 사용자 지정해야 하는 경우, `WandbCallback`을 서브클래싱하고 Trainer 클래스의 추가 기능을 활용하는 기능을 덧붙여 이 콜백을 수정할 수 있습니다.
아래에는 이 새 콜백을 HF Trainer에 추가하는 일반적인 패턴이 나와 있으며, 더 아래에는 평가 출력을 W\&B Table에 로깅하는 전체 코드 예제가 나와 있습니다:
```python theme={null}
# 평소와 같이 Trainer를 인스턴스화합니다
trainer = Trainer()
# 새 로깅 콜백을 인스턴스화하고 Trainer 객체를 전달합니다
evals_callback = WandbEvalsCallback(trainer, tokenizer, ...)
# Trainer에 콜백을 추가합니다
trainer.add_callback(evals_callback)
# 평소와 같이 Trainer 트레이닝을 시작합니다
trainer.train()
```
#### 트레이닝 중 평가 샘플 보기
다음 섹션에서는 트레이닝 중에 모델 예측을 실행하고 평가 샘플을 W\&B Table에 로깅하도록 `WandbCallback`을 사용자 지정하는 방법을 보여줍니다. `eval_steps`마다 Trainer 콜백의 `on_evaluate` 방법을 사용합니다.
여기서는 tokenizer를 사용해 모델 출력의 예측과 레이블을 디코딩하는 `decode_predictions` 함수를 작성합니다.
그런 다음 예측과 레이블로 pandas 데이터프레임을 만들고, 데이터프레임에 `epoch` column을 추가합니다.
마지막으로 데이터프레임으로 `wandb.Table`을 생성하고 이를 wandb에 로깅합니다.
또한 `freq` 에포크마다 예측을 로깅하여 로깅 빈도를 제어할 수 있습니다.
**참고**: 일반 `WandbCallback`과 달리, 이 맞춤형 콜백은 `Trainer` 초기화 중이 아니라 `Trainer`가 인스턴스화된 **후에** trainer에 추가해야 합니다.
이는 초기화 시 `Trainer` 인스턴스가 콜백에 전달되기 때문입니다.
```python theme={null}
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions(tokenizer, predictions):
labels = tokenizer.batch_decode(predictions.label_ids)
logits = predictions.predictions.argmax(axis=-1)
prediction_text = tokenizer.batch_decode(logits)
return {"labels": labels, "predictions": prediction_text}
class WandbPredictionProgressCallback(WandbCallback):
"""트레이닝 중 모델 예측을 로깅하는 맞춤형 WandbCallback.
이 콜백은 트레이닝 중 각 로깅 단계에서 모델 예측과 레이블을 wandb.Table에 로깅합니다.
트레이닝이 진행됨에 따라 모델 예측을 시각화할 수 있습니다.
Attributes:
trainer (Trainer): Hugging Face Trainer 인스턴스.
tokenizer (AutoTokenizer): 모델과 연결된 tokenizer.
sample_dataset (Dataset): 예측 생성을 위한 검증 데이터셋의 서브셋.
num_samples (int, optional): 예측 생성을 위해 검증 데이터셋에서 선택할 샘플 수. 기본값은 100.
freq (int, optional): 로깅 빈도. 기본값은 2.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples=100, freq=2):
"""WandbPredictionProgressCallback 인스턴스를 초기화합니다.
Args:
trainer (Trainer): Hugging Face Trainer 인스턴스.
tokenizer (AutoTokenizer): 모델과 연결된 tokenizer.
val_dataset (Dataset): 검증 데이터셋.
num_samples (int, optional): 예측 생성을 위해 검증 데이터셋에서 선택할 샘플 수.
기본값은 100.
freq (int, optional): 로깅 빈도. 기본값은 2.
"""
super().__init__()
self.trainer = trainer
self.tokenizer = tokenizer
self.sample_dataset = val_dataset.select(range(num_samples))
self.freq = freq
def on_evaluate(self, args, state, control, **kwargs):
super().on_evaluate(args, state, control, **kwargs)
# `freq` 에포크마다 예측을 로깅하여 로깅 빈도를 제어합니다
if state.epoch % self.freq == 0:
# 예측 생성
predictions = self.trainer.predict(self.sample_dataset)
# 예측과 레이블 디코딩
predictions = decode_predictions(self.tokenizer, predictions)
# wandb.Table에 예측 추가
predictions_df = pd.DataFrame(predictions)
predictions_df["epoch"] = state.epoch
records_table = self._wandb.Table(dataframe=predictions_df)
# wandb에 테이블 로깅
self._wandb.log({"sample_predictions": records_table})
# 먼저 Trainer를 인스턴스화합니다
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
# WandbPredictionProgressCallback을 인스턴스화합니다
progress_callback = WandbPredictionProgressCallback(
trainer=trainer,
tokenizer=tokenizer,
val_dataset=lm_dataset["validation"],
num_samples=10,
freq=2,
)
# trainer에 콜백을 추가합니다
trainer.add_callback(progress_callback)
```
더 자세한 예시는 이 [colab](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Custom_Progress_Callback.ipynb)을 참고하세요.
### 추가로 사용할 수 있는 W\&B 설정은 무엇인가요?
환경 변수를 설정하면 `Trainer`에서 무엇을 로깅할지 더 세부적으로 설정할 수 있습니다. W\&B 환경 변수의 전체 목록은 [여기](/ko/platform/hosting/env-vars)에서 확인할 수 있습니다.
| 환경 변수 | 사용 |
| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `WANDB_PROJECT` | 프로젝트 이름을 지정합니다(기본값: `huggingface`) |
| `WANDB_LOG_MODEL` | 모델 체크포인트를 W\&B Artifact로 로깅합니다(기본값: `false`)
false(기본값): 모델 체크포인트를 저장하지 않음checkpoint: 체크포인트를 args.save\_steps마다 업로드합니다(Trainer의 TrainingArguments에서 설정).end: 트레이닝이 끝날 때 최종 모델 체크포인트를 업로드합니다.
모델의 그라디언트, 파라미터를 로깅할지, 또는 둘 다 로깅하지 않을지 설정합니다
false(기본값): 그라디언트 또는 파라미터를 로깅하지 않음gradients: 그라디언트의 히스토그램을 로깅합니다all: 그라디언트와 파라미터의 히스토그램을 로깅합니다
### `wandb.init()`를 어떻게 사용자 지정하나요?
`Trainer`가 사용하는 `WandbCallback`은 `Trainer`가 초기화되면 내부적으로 `wandb.init()`를 호출합니다. 또는 `Trainer`를 초기화하기 전에 `wandb.init()`를 호출해 run을 수동으로 설정할 수도 있습니다. 이렇게 하면 W\&B run 설정을 완전히 제어할 수 있습니다.
`init`에 전달할 수 있는 항목의 예시는 아래와 같습니다. `wandb.init()`의 자세한 내용은 [`wandb.init()` 레퍼런스](/ko/models/ref/python/functions/init)를 참조하세요.
```python theme={null}
wandb.init(
project="amazon_sentiment_analysis",
name="bert-base-high-lr",
tags=["baseline", "high-lr"],
group="bert",
)
```
## 추가 리소스
아래는 흥미롭게 읽어볼 만한 Transformers 및 W\&B 관련 글 6편입니다
Hugging Face Transformers를 위한 하이퍼파라미터 최적화
* Hugging Face Transformers의 하이퍼파라미터 최적화 전략 세 가지인 Grid Search, Bayesian Optimization, Population Based Training을 비교합니다. * Hugging Face transformers의 표준 uncased BERT 모델을 사용해 SuperGLUE 벤치마크의 RTE 데이터셋에서 파인튜닝을 수행합니다. * 결과적으로 Population Based Training이 Hugging Face transformer 모델의 하이퍼파라미터 최적화에 가장 효과적인 접근 방식임을 보여줍니다. [Hyperparameter Optimization for Hugging Face Transformers 리포트](https://wandb.ai/amogkam/transformers/reports/Hyperparameter-Optimization-for-Hugging-Face-Transformers--VmlldzoyMTc2ODI)를 읽어보세요.Hugging Tweets: 트윗을 생성하는 모델 트레이닝하기
* 이 글에서 저자는 누구나 자신의 트윗으로 사전 트레이닝된 GPT2 HuggingFace Transformer 모델을 5분 안에 파인튜닝하는 방법을 보여줍니다. * 이 모델은 다음과 같은 파이프라인을 사용합니다: 트윗 다운로드, 데이터셋 최적화, 초기 실험, 사용자 간 loss 비교, 모델 파인튜닝. 전체 리포트는 [여기](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI)에서 읽어보세요.Hugging Face BERT와 WB를 사용한 문장 분류
* 이 글에서는 NLP에 전이 학습을 적용하는 데 초점을 맞춰, 최근 자연어 처리의 발전을 활용한 문장 분류기를 만들어 보겠습니다. * 단일 문장 분류를 위해 The Corpus of Linguistic Acceptability(CoLA) 데이터셋을 사용할 예정이며, 이 데이터셋은 2018년 5월에 처음 공개된, 문법적으로 올바른 문장과 올바르지 않은 문장에 레이블을 붙인 문장 집합입니다. * 다양한 NLP 작업에서 최소한의 노력으로 고성능 모델을 만들기 위해 Google의 BERT를 사용하겠습니다. 전체 리포트는 [여기](https://wandb.ai/cayush/bert-finetuning/reports/Sentence-Classification-With-Huggingface-BERT-and-W-B--Vmlldzo4MDMwNA)에서 읽어보세요.Hugging Face 모델 성능 tracking 단계별 가이드
* W\&B와 Hugging Face transformers를 사용해 BERT보다 40% 더 작지만 BERT 정확도의 97%를 유지하는 Transformer인 DistilBERT를 GLUE 벤치마크에서 트레이닝합니다. * GLUE 벤치마크는 NLP 모델 트레이닝을 위한 9개의 데이터셋과 작업으로 이루어진 모음입니다. 전체 리포트는 [여기](https://wandb.ai/jxmorris12/huggingface-demo/reports/A-Step-by-Step-Guide-to-Tracking-HuggingFace-Model-Performance--VmlldzoxMDE2MTU)에서 읽어보세요.HuggingFace의 Early Stopping 예제
* Early Stopping 정규화를 사용한 Hugging Face Transformer 파인튜닝은 PyTorch나 TensorFlow에서 기본적으로 수행할 수 있습니다. * TensorFlow에서는 `tf.keras.callbacks.EarlyStopping` 콜백을 사용해 EarlyStopping 콜백을 손쉽게 적용할 수 있습니다. * PyTorch에는 바로 사용할 수 있는 early stopping 방법이 없지만, GitHub Gist에서 동작하는 early stopping hook을 사용할 수 있습니다. 전체 리포트는 [여기](https://wandb.ai/ayush-thakur/huggingface/reports/Early-Stopping-in-HuggingFace-Examples--Vmlldzo0MzE2MTM)에서 읽어보세요.맞춤형 데이터셋에서 Hugging Face Transformers를 파인튜닝하는 방법
감성 분석(이진 분류)을 위해 맞춤형 IMDB 데이터셋에서 DistilBERT transformer를 파인튜닝합니다. 전체 리포트는 [여기](https://wandb.ai/ayush-thakur/huggingface/reports/How-to-Fine-Tune-HuggingFace-Transformers-on-a-Custom-Dataset--Vmlldzo0MzQ2MDc)에서 읽어보세요.
## 도움 받기 또는 기능 요청
Hugging Face W\&B 인테그레이션과 관련해 문제나 질문이 있거나 기능을 요청하려면 [Hugging Face 포럼의 이 스레드](https://discuss.huggingface.co/t/logging-experiment-tracking-with-w-b/498)에 글을 올리거나 Hugging Face [Transformers GitHub repo](https://github.com/huggingface/transformers)에서 이슈를 열어 주세요.