> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-docs-sandboxes-integrations-placement.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
> W&B 内でモデル チェックポイントまたはホスト型 API モデルを評価し、自動生成されるリーダーボードを使って結果を分析します。
# LLM 評価ジョブ
[LLM Evaluation Jobs](/ja/models/launch) は、CoreWeave が管理するインフラストラクチャーを利用して LLM モデルのパフォーマンスを評価するためのベンチマーク フレームワークです。最新の業界標準に準拠した包括的な[モデル評価ベンチマーク](/ja/models/launch/evaluations)から選択し、W\&B Models の自動リーダーボードやチャートを使って結果の確認、分析、共有を行えます。LLM Evaluation Jobs を使えば、GPU インフラストラクチャーを自分でデプロイして維持管理する複雑さを解消できます。
LLM 評価ジョブは、[W\&B Multi-tenant Cloud](/ja/platform/hosting/hosting-options/multi_tenant_cloud) で**プレビュー**版として提供されています。プレビュー期間中は、コンピュートを無料で利用できます。詳細については、[LLM 評価ジョブの pricing](/ja/models/launch#pricing)を参照してください。
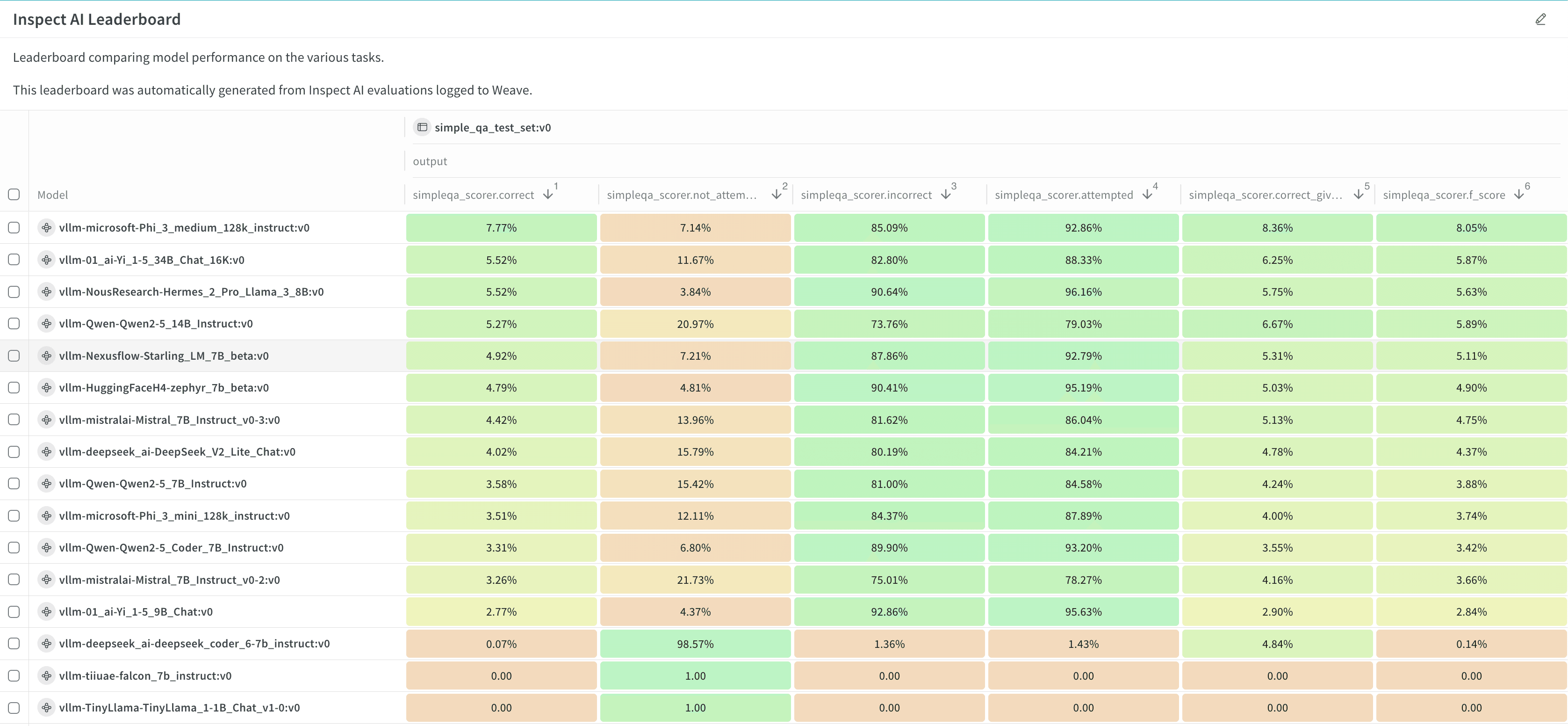
## 仕組み
モデル チェックポイントまたは一般公開されているホスト型の OpenAI 互換モデルを、わずか数 step で評価できます。
1. W\&B Models で評価ジョブを設定します。ベンチマークや設定 (リーダーボードを生成するかどうかなど) を定義します。
2. 評価ジョブを Launch します。
3. 結果とリーダーボードを確認し、分析します。
同じ宛先プロジェクトに対して評価ジョブを Launch するたびに、そのプロジェクトのリーダーボードは自動的に更新されます。
## 次のステップ
* [評価ベンチマークカタログ](/ja/models/launch/evaluations)を参照する
* [モデル チェックポイントを評価する](/ja/models/launch/evaluate-model-checkpoint)
* [APIでホストされているモデルを評価する](/ja/models/launch/evaluate-hosted-model)
## 詳細情報
### Pricing
LLM Evaluation Jobs は、モデル チェックポイントまたはホスト型 API を、一般的なベンチマークに対してフルマネージドの CoreWeave コンピュート上で評価します。インフラストラクチャーを管理する必要はありません。料金は、アイドル時間ではなく、実際に消費したリソースに対してのみ発生します。料金は、コンピュートとストレージの 2 つの要素で構成されます。コンピュートはパブリックプレビュー期間中は無料で、料金は一般提供時にお知らせします。保存される結果には、メトリクスと、Models の runs に保存された各サンプルのトレースが含まれます。ストレージは、データ量に応じて毎月課金されます。プレビュー期間中、LLM Evaluation Jobs を利用できるのは Multi-tenant Cloud のみです。詳しくは [Pricing](https://wandb.ai/pricing) ページを参照してください。
### ジョブの制限
個々の評価ジョブには、次の制限があります。
* 評価対象のモデルの最大サイズは、コンテキストを含めて 86 GB です。
* 各ジョブで使用できる GPU は 2 基までです。
### 要件
* モデル チェックポイントを評価するには、モデルの重みを VLLM 互換のartifactとしてパッケージ化する必要があります。詳細とコード例については、[例: モデルを準備する](/ja/models/launch/evaluate-model-checkpoint#example-prepare-a-model)を参照してください。
* OpenAI 互換モデルを評価するには、そのモデルに公開 URL でアクセスできる必要があります。また、認証用のAPIキーを含むチームシークレットを、組織またはチーム管理者が設定する必要があります。
* 一部のベンチマークでは、スコアリングに OpenAI モデルを使用します。これらのベンチマークを実行するには、組織またはチーム管理者が必要なAPIキーを含むチームシークレットを設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、[評価ベンチマークカタログ](/ja/models/launch/evaluations)を参照してください。
* 一部のベンチマークでは、Hugging Face のgated datasetへのアクセスが必要です。これらのベンチマークのいずれかを実行するには、組織またはチーム管理者が Hugging Face でgated datasetへのアクセスをリクエストし、Hugging Face のユーザーアクセストークンを生成して、チームシークレットとして設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、[評価ベンチマークカタログ](/ja/models/launch/evaluations)を参照してください。
これらの要件を満たすための詳細と手順については、以下を参照してください。
* [モデル チェックポイントを評価する](/ja/models/launch/evaluate-model-checkpoint)
* [ホスト型 API モデルを評価する](/ja/models/launch/evaluate-hosted-model)